At work I write code that lies to other code. The polite name is “scraping.” The honest name is: they put up a wall, I climb over it. They check who I am, my code says something true enough to pass. They look harder, my code looks back differently.
At Activate Intelligence one of our clients is one of the largest public affairs firms in Italy. For them we do media monitoring, research, and data aggregation across general governmental websites. That is where the scraper lives. Most of the targets are Italian government sites, which are quite bad and quite different from each other. None of them are hostile by design. None of them are particularly friendly either.
The first version of the scraper was the laziest thing that works: Python requests, a custom user agent. That handles a lot of what we need. It died at the Italian Senate website. The page rendered fine in a browser. From requests, it came back as an empty shell, because the content loads from JavaScript after the initial response.
So I added a browser. Headless Chromium. The architecture became a ladder: a request walks down the tiers until one of them succeeds.
Tier 1 is a Scrapy spider. Cheap, fast, gives us back HTML if the page is mostly static. Tier 2 is curl_cffi, which is a fork of curl that knows how to impersonate the TLS fingerprint of a real Chrome. It is still not running JavaScript, but it survives the kind of WAF check that only inspects the handshake. Tier 3 is the expensive option: a headless Chromium driven by Playwright (the patched fork, Patchright), with a persistent profile, that can actually render a page. Tier 3.5, which I keep for the meaner sites, is Camoufox: a Firefox fork with stealth patches compiled in at the C++ level.
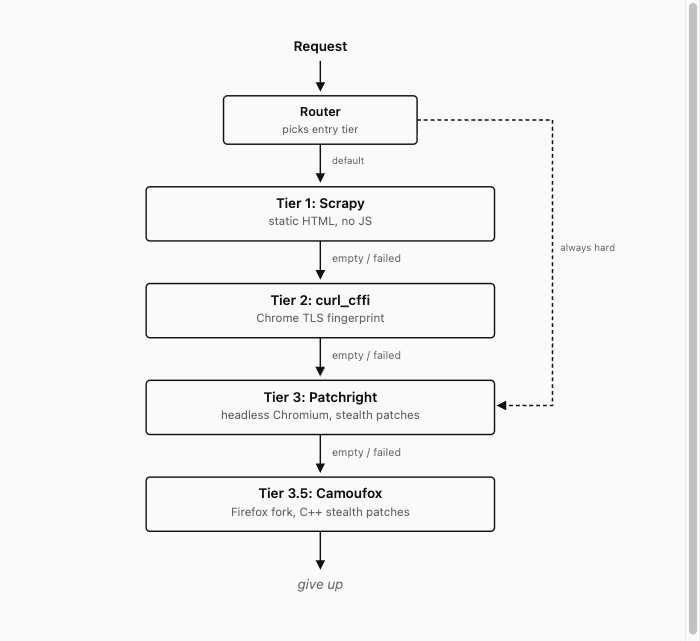
Most requests resolve at Tier 1. A few make it to Tier 3. The cost difference per request is large enough that the order of the ladder matters more than any single tier’s cleverness.
But the ladder is not strictly walked top to bottom either. The diagram above is the cold-start path. In practice there is a small router up front that picks where to enter:
def fetch(url, render=False):
start = pick_entry_tier(url, render) # known hard? jump to T3.
# known cheap? stay at T1.
for tier in TIERS[start:]:
result = tier.try_fetch(url)
if result.looks_real():
return result
return give_up(url)
pick_entry_tier is small and dumb on purpose. It checks a static list of hosts we already know need the heavy browser, then a per-domain preference flag from past observations that either pins the host to Tier 3 (“always hard”) or to Tier 1 (“always cheap, do not bother climbing”). Everything else cold-defaults to Tier 1.
Right now this picker is a static list plus the flag. The eventual plan is having it learn from outcomes: every successful fetch tells us which tier was actually right for that host, and over enough requests the router can pick correctly without anyone curating a list. That telemetry is being collected in shadow now. The router emits what it would have chosen as a CloudWatch metric, the old ladder runs unchanged, and I compare.
The hard part of any of this is looks_real(). A page can come back with HTTP 200, fully rendered, and still not be the page. The site can serve a polite empty shell, or a “we noticed you are a bot” page that pretends to be the real one. Telling those apart is most of the work.
That held for a while. Then the Senate website started giving me problems again. Not 403s exactly. The page would load, but it knew. It knew the browser was headless, it knew it was Playwright, and it served back something polite and useless instead of the real content.
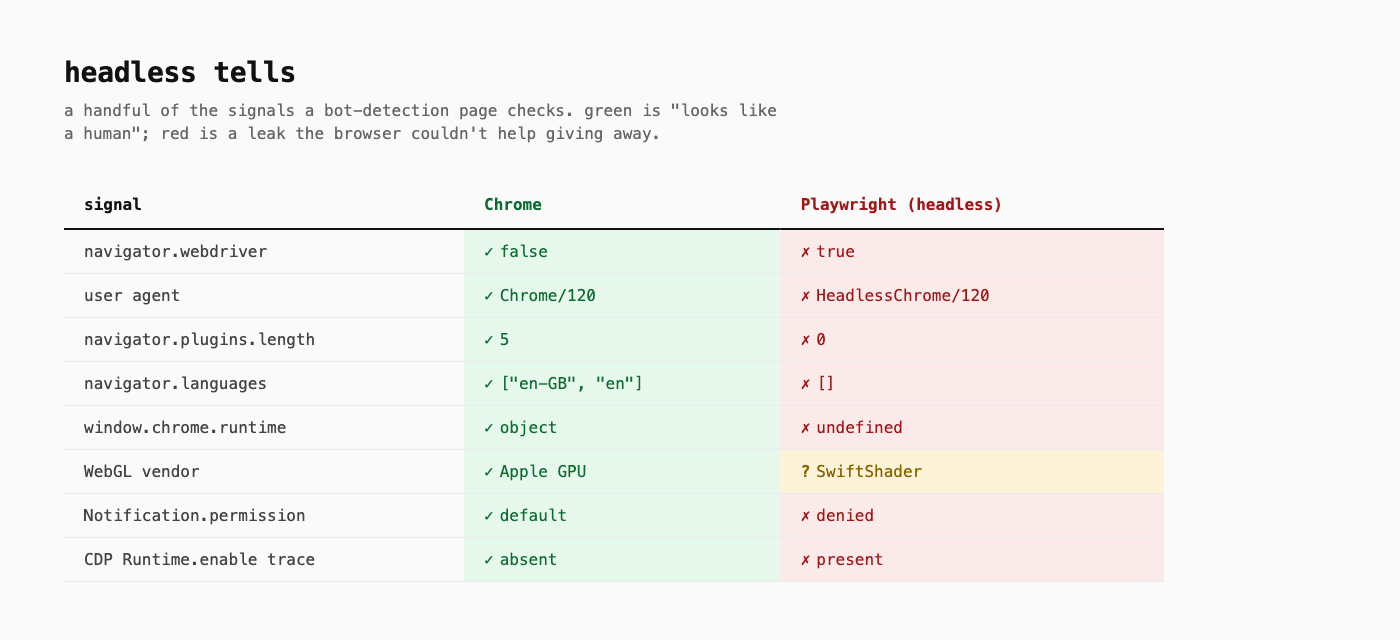
This is the part of the project I had not appreciated before doing it: a real Chromium and a Playwright-driven Chromium are not the same browser. They expose different signals. The CDP protocol that Playwright uses to talk to the browser leaves a trace. The HeadlessChrome token shows up in places it shouldn’t. There is a debug endpoint, Runtime.enable, that the moment it gets called, tells the page “this is automation.” None of this is documented as a leak. It is just how the thing works. The browser tells on itself.
It leaked the info of being a bot, which is a sentence I would not have understood three months ago and now feels obvious. Of course it leaks. There is no reason a thing built for testing would also be invisible.
This is what Patchright and Camoufox exist for. They are not magic. They patch the specific leaks: rewrite the Runtime.enable path so it does not announce itself, drop the HeadlessChrome token, and a long list of smaller signals. The point is not which fork. The point is that the abstraction called “headless browser” is leaky enough that an entire small industry exists to plug the leaks, and the sites that care can tell the difference between a real human Chrome and the patched stealth Chrome that is trying very hard to look like one. Some of them are good at it. Some are not. You find out by hitting the site.
The other thing that surprised me is how much of this can be cached. The first time a request hits a protected site, the WAF (Cloudflare, AWS WAF, DataDome, whatever it is that day) makes the browser solve a small challenge: a JavaScript puzzle, a cookie issued at the end of it, sometimes a localStorage write. Once the challenge passes, the cookie is valid for a while. So the trick is to solve the challenge once in the slow browser, save the cookies and localStorage into DynamoDB keyed by the WAF engine and the host, and the next time anyone hits the same host you replay the saved state and skip the challenge entirely.
The key format ended up being:
waf-state#<engine>#<scheme>#<exact-host>
engine is which WAF I detected. host is exact on purpose: www.senato.it and senato.it are stored as separate entries, because the WAF treats them differently and I found that out the hard way. The state itself is gzipped and base64 encoded, because cookies plus localStorage are bigger than you would think. The TTL matches roughly how long the WAF’s session token tends to last.
This was not a clever idea. It was just the next obvious thing once you had seen the same site get challenged over and over for no reason. Why solve it every time if you can solve it once.
Sitting on top of all this is a small quota. Ten requests per second per domain, and a circuit breaker that opens after five consecutive failures and stays open for a minute before letting a single probe through. Not because the targets ask for it, but because hammering a half-broken site is the fastest way to turn a transient blip into a hard ban.
The whole thing runs on AWS Lambda. Which means everything I just described, the three browser tiers and the WAF cache and the per-domain rate limit, all has to fit inside a container image that boots in a few seconds, with two gigabytes of ephemeral disk, and no persistent storage between invocations. That constraint is half the design. The other half is the contest with the sites.
Here is the funniest thing I learned. The Italian Ministry of Transport website is blocked from outside the EU. Not the data, not a login wall, the entire site. If your request comes from an IP that is not European, you do not get to read about Italian transport policy. And it is not the only one. There is a small category of government website that has decided people outside Europe do not deserve to know what is going on. I cannot tell if that is the point or an accident. Either way, the scraper has to live in the right region just to look like a normal user.
People sometimes ask whether there is an irony here. Public records, public data, sitting behind Cloudflare, requiring an arms race to read. I do not feel the irony, honestly. The sites are bad, the scrapers route around the badness, the badness gets a little better, the scrapers route around that. It feels less like injustice and more like a slightly stupid game that nobody is going to win. Petty on both sides.
If I had to describe the project to a non-technical friend I would struggle. I do not have a good one-liner for it. The closest honest version is: I taught a program to convincingly pretend to be a person reading a website, because the website is run by people who do not want a program reading it, even though the website is public.
What I like about this work, if I am honest about it, is that it is petty in a clean way. They do something to stop me. I do something to get past it. I am not pretending it is a noble fight. It is two pieces of code, neither of which can feel anything, taking turns being slightly cleverer than the other, on behalf of someone who just wants to read a page.
Whether there is a Tier 4 in this depends on the data. Probably in a couple of weeks or months something else will break, and I’ll write the next rung. At some point the Lambda constraint also stops paying for itself. Two gigabytes of disk and a few-second cold start is a tight box for a persistent stealth browser with a real profile, and the slow tiers will eventually move to a small EC2. That is a future problem.
The shape of the thing does not change though. The sites will find a new signal to check. Somebody will patch the next browser fork. The next WAF will get a quirk worth exploiting. There is no version of this where one side wins. There is only the next rung, and the one after that.


